Längst setzen Unternehmen nicht mehr auf einen einzigen Cloud-Provider, sondern greifen je nach Einsatzszenario auf unterschiedliche Anbieter zurück. Dieser Multi-Cloud-Ansatz verringert Abhängigkeiten, schafft Flexibilität und trägt zur Kostenoptimierung bei. In Bezug auf Speicherdienste könnte ein Unternehmen somit beispielsweise einen S3 Objektspeicher, wie bspw. Scality RING, vor Ort als primäre Speicherlokation verwenden und zusätzlich eine Teilmenge der Daten bei einem oder mehreren Hyperscaler speichern, um dortige Analyse-Tools und Compute-Ressourcen zu nutzen. Gleichzeitig wird eine Kopie der Daten auf Grund von Compliance-Vorgaben langfristig archiviert, z.B. mit Hilfe des PoINT Archival Gateway auf Tape.
Bei einem solchen Szenario stellt sich natürlich die Frage nach dem Management und der Transparenz für die Anwendung. Abhilfe schafft hier Scality Zenko, ein Multi Cloud Data Controller, der mehrere Clouds unter einem Namespace zusammenfasst. Zenko unterstützt One-to-One und One-to-Many Replikationen und Lifecycle Policies. Als übergeordnete Schicht bietet Zenko auch eine Metadaten-Suche.
Die Kombination aus Scality Zenko zusammen mit dem PoINT Archival Gateway ermöglicht sehr interessante Use Cases.
- Für den Fall, dass eine Cloud ausfällt oder S3 Objekte mutwillig gelöscht werden, sollten Unternehmen mit einer unabhängigen Kopie vorsorgen. Als Tape-basierter S3 Objektspeicher stellt das PoINT Archival Gateway eine äußerst kostengünstige Plattform für diesen Zweck bereit. Zenko sorgt dafür, dass Daten auf dem primären Objektspeicher abgelegt werden und eine Kopie an das PoINT Archival Gateway gesendet wird. Einzelne Objekte können im Bedarfsfall mit einem beliebigen S3 Client direkt vom PoINT Archival Gateway wiederhergestellt werden. Im Vergleich zu einer gewöhnlichen Cross Region Replication (CRR), die viele Objektspeicher bieten, kann Zenko im Fehlerfall unter Beibehaltung des Namespace vom Replikat lesen. Ohne Zenko wäre eine Umkonfiguration des Zugriffpunktes in den S3 Clients notwendig.
- Neben der Datensicherung eignet sich das PoINT Archival Gateway hervorragend für die langfristige Archivierung inaktiver Objekte. Mittels einer Lifecycle Rule werden bspw. alle Objekte, die vor 30 Tagen erzeugt wurden, vom primären festplatten-basierten Objektspeicher auf das Tape-basierte PoINT Archival Gateway verdrängt. Die Verlagerung und der Zugriff erfolgen transparent über Scality Zenko.
Für die Administration von Scality Zenko steht mit Orbit eine grafische Oberfläche zur Verfügung.
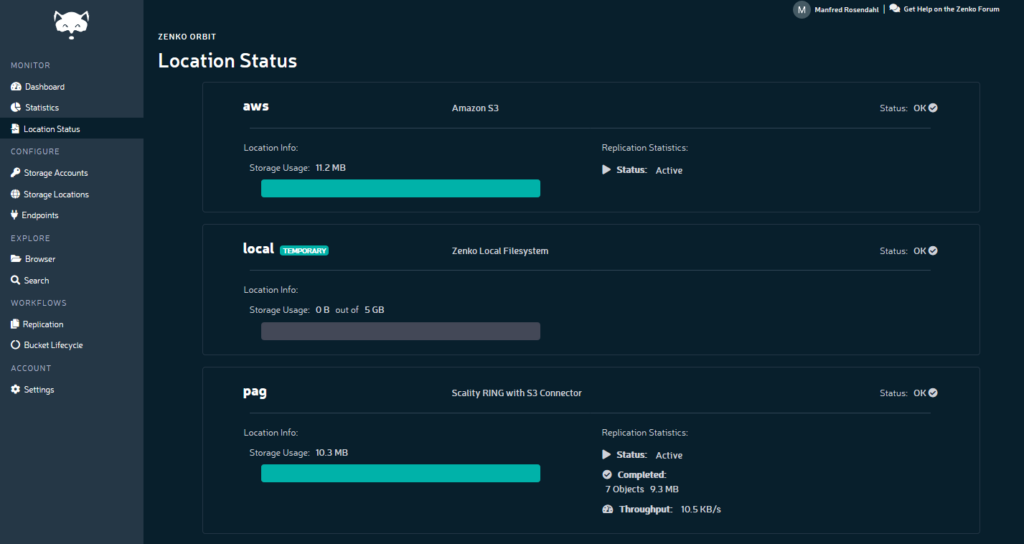
Um mehrere Objektspeicher bzw. Cloud Provider in einen Namespace einzubinden, werden diese im ersten Schritt als sog. Cloud Location in Zenko registriert. Hierzu werden die entsprechenden Parameter wie URL, der eigentliche Ziel-Bucket sowie die Zugangsdaten angegeben. Beim Anlegen einer Location muss die Entscheidung getroffen werden, ob mit einem Source-Bucket-Prefix oder ohne gearbeitet wird. Das heißt: Ein Objekt wird entweder direkt in den Target-Bucket geschrieben oder es wird ein Prefix vorangestellt, das dem Bucket-Namen im Zenko Namespace entspricht. Ohne Prefix muss natürlich bedacht werden, dass es zu Konflikten kommen kann, wenn mehrere Buckets aus Zenko heraus in das gleiche Ziel-Bucket verweisen.
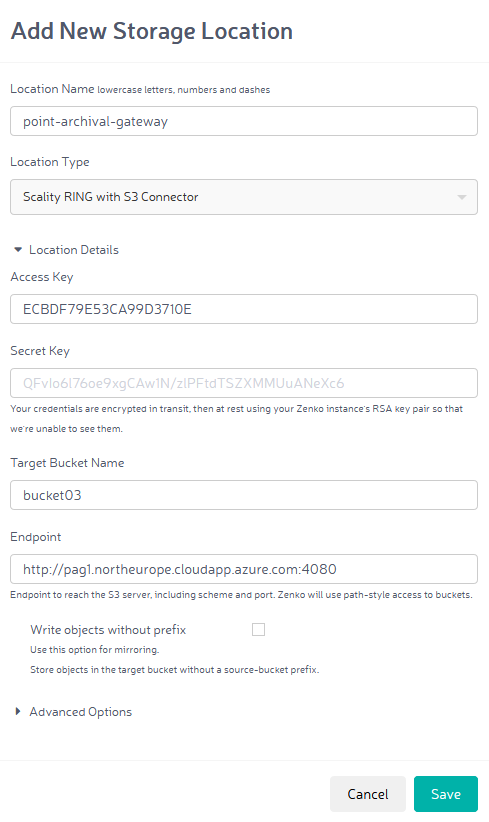
Nach Registrierung der Objektspeicher und Cloud Provider können Buckets in Zenko angelegt werden. Hierbei wird definiert, in welcher Lokation die Objekte gespeichert werden. Applikationen bzw. S3 Clients verwenden Buckets im Zenko Namespace und kommunizieren somit indirekt mit dem eigentlichen Speicherziel. Ein interessanter Aspekt bei dieser Art „Virtualisierung“ ist, dass Clients mit Zenko via S3 sprechen und als Backend aber auch Microsoft Azure unterstützt wird, das selbst keine S3 API bietet.

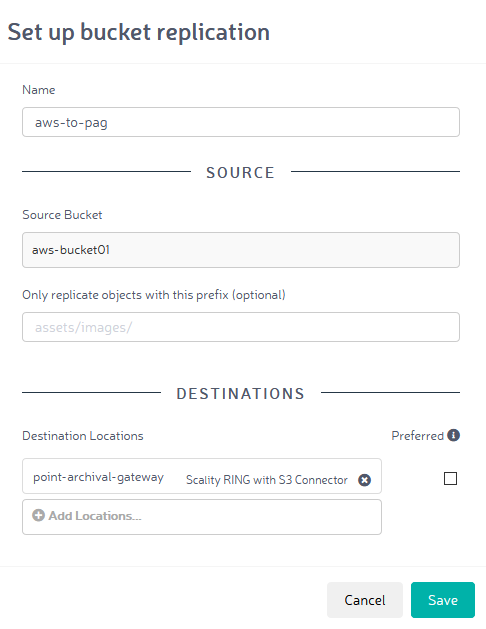
Die Replikations-Option in Zenko erlaubt die Angabe von einem oder mehreren Zielen. Im nachfolgenden Screenshot wird als Beispiel eine Replikation von AWS zum PoINT Archival Gateway konfiguriert. D.h. Clients schreiben Objekte in den Zenko Bucket „aws-bucket01“, dessen Backend die AWS Cloud ist. Asynchron erfolgt eine Replikation auf Tape. Werden nun versehentlich oder mutwillig Objekte bei AWS gelöscht, genügt das Setzen der sog. „Preferred Read“ Option. Applikationen können dann weiterhin Objekte lesen, aber nun aus dem Backup auf dem PoINT Archival Gateway. Der Zugriffspunkt für die S3 Clients ändert sich nicht – für diese Transparenz sorgt Zenko.
Dient ein Cloud Provider als Replikationsquelle, so müssen mögliche Kosten für das Lesen (Egress Kosten) bedacht werden. Diese Problematik kann umgangen werden, indem Zenko als vorübergehende Lokation konfiguriert wird. Sobald die Replikation zu allen Zielen abgeschlossen ist, werden die Daten aus dem temporären Speicher gelöscht.
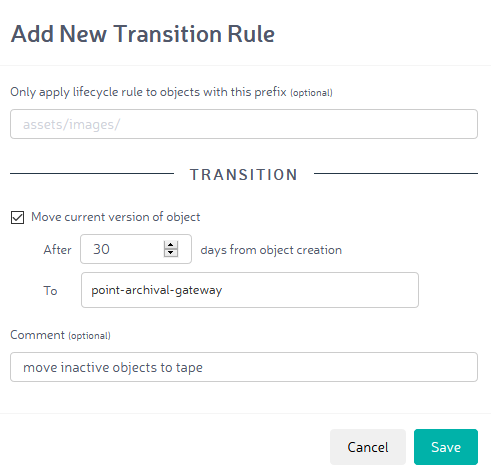
Soll keine Kopie der Objekte auf dem PoINT Archival Gateway erstellt werden, sondern sollen inaktive Objekte auf dem System archiviert werden, so geschieht dies über eine Transition Rule in Zenko. Im folgenden Beispiel werden alle Objekte, deren Erstellungsdatum 30 Tage zurückliegt, vom primären Speicherort auf das PoINT Archival Gateway übertragen. Dank der Tape-Technologie werden die Kosten pro GB deutlich reduziert.
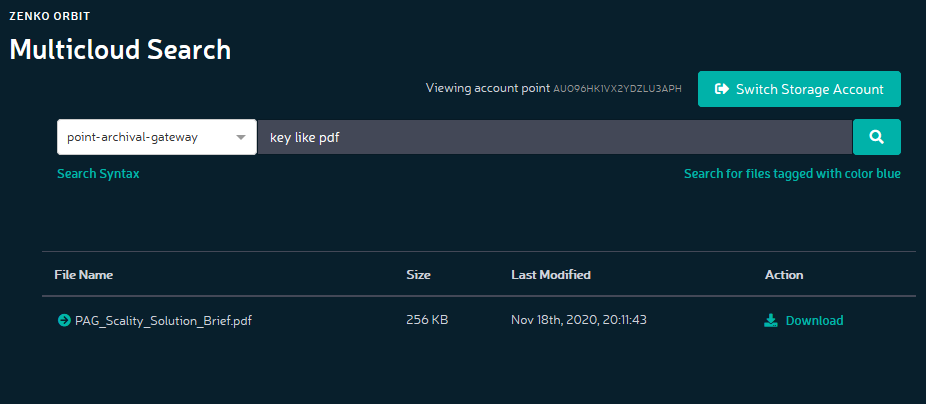
Die S3 REST API bietet bisher keine Möglichkeit, um nach Objekten zu suchen. Zenko erweitert den Funktionsumfang durch eine Metadaten-Suche. Hierzu wird ein S3 GET Request durch einen Search Parameter ergänzt. Alternativ können Suchanfragen auch über die Orbit Web-GUI gestellt werden.