For some time now, businesses have avoided relying on just one cloud provider, instead working with various services depending on the use case. This multi-cloud approach reduces dependencies, increases flexibility and helps optimize costs. When it comes to storage services, for example, a company could use an on-site S3 object storage system like Scality RING as its primary storage location, as well as saving some of the data to one or more hyperscalers in order to use their analytical tools and computing resources. Meanwhile, for compliance purposes, a copy of the data is stored in a long-term archive, for example on tape with the help of the PoINT Archival Gateway.
In this kind of scenario, there are bound to be questions about how such an application is managed, as well as its transparency. This issue can be remedied using Scality Zenko, a multi-cloud data controller that brings multiple clouds together under one namespace. Zenko supports one-to-one and one-to-many replication, as well as life cycle policies. Thanks to its overarching perspective, Zenko also offers metadata searching.
Combining Scality Zenko with the PoINT Archival Gateway enables a number of very interesting use cases.
- If a cloud goes down or S3 objects are deliberately deleted, businesses need to be ready with a separate replacement copy. As a tape-based S3 object storage system, the PoINT Archival Gateway represents a particularly cost-effective platform for this purpose. Zenko ensures that data is saved to the primary object storage system and that a copy is sent to the PoINT Archival Gateway. Individual objects can be restored if needed, directly from the PoINT Archival Gateway, using any S3 client. Unlike the ordinary cross-region replication (CRR) offered by many object storage systems, Zenko can read from the replica while still using the same namespace. Without Zenko, you would need to reconfigure the access point within the S3 client.
- As well as securing data, the PoINT Archival Gateway is an excellent choice for long-term archiving of inactive objects. A life cycle rule can be used to move, say, all objects created more than 30 days ago from the primary hard disk-based object storage system to the tape-based PoINT Archival Gateway. Scality Zenko transfers and accesses the data transparently.
A graphical interface named Orbit allows access to Scality Zenko’s administrative tools.
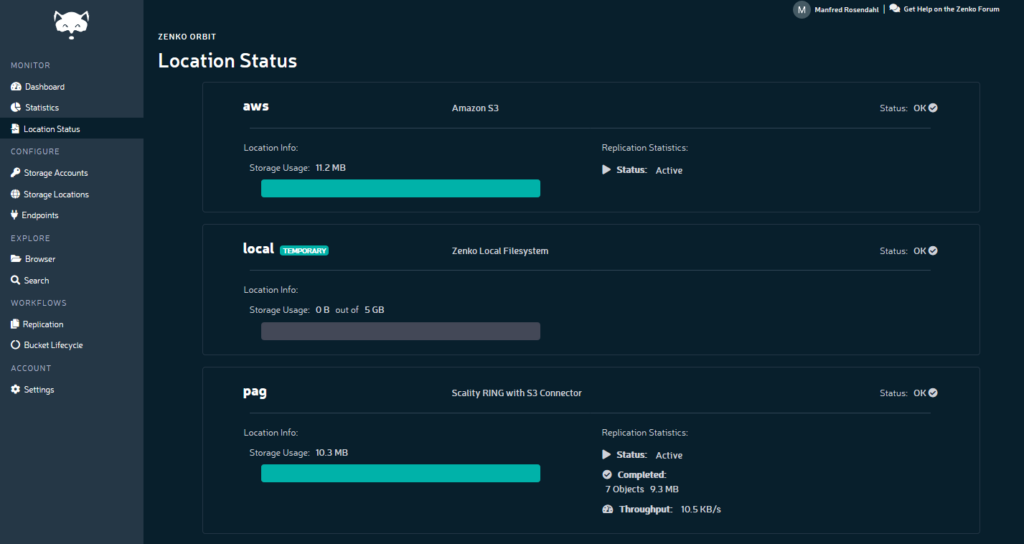
In order to integrate multiple object storage systems or cloud providers into one namespace, they are first registered as “cloud locations” in Zenko. The relevant parameters, such as the URL, actual target bucket and login information, are entered at this time. When setting up a location, you will need to decide whether to operate with or without a source bucket prefix. What this means in practice is that either an object will be written directly to the target bucket, or a prefix will be appended at the start that represents the bucket name within the Zenko namespace. If no prefix is attached, of course, it is important to remember that there can be conflicts if multiple buckets point from Zenko to the same target.
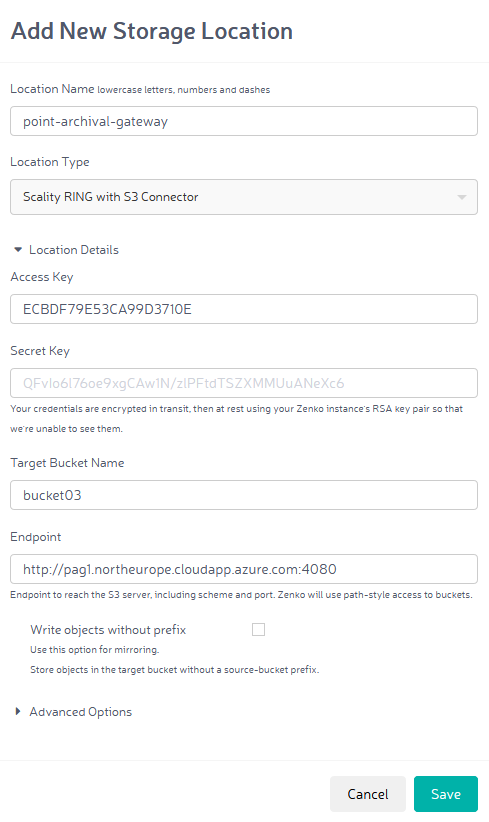
After the object storage systems and cloud providers are registered, you can create buckets in Zenko. Here, you define where the objects will be saved. Applications and S3 clients use buckets within the Zenko namespace and therefore communicate indirectly with the actual target location. An interesting aspect of this kind of “virtualization” is that clients talk to Zenko via S3, and Microsoft Azure is also supported via the back end, even though it does not have an S3 API itself.

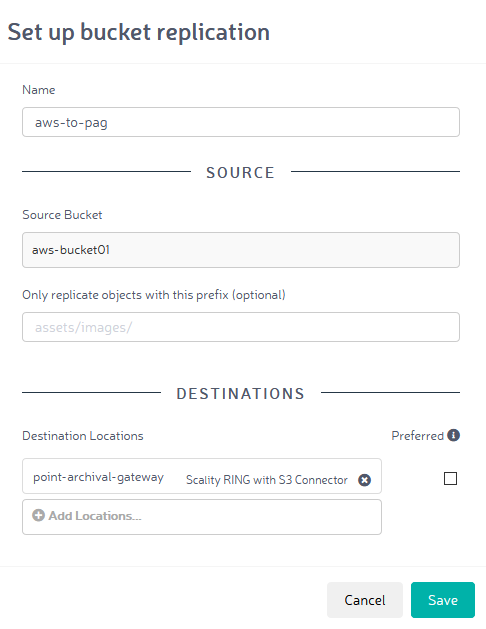
The replication option in Zenko lets you specify one or several targets. The screenshot below shows an example configuration for replicating from AWS to PoINT Archival Gateway. This means clients write objects to the Zenko bucket “aws-bucket01”, whose back end points to the AWS cloud. Data is replicated asynchronously on tape. Now, if objects are ever accidentally or deliberately deleted from AWS, all you need to do is change the “Preferred Read” option. Applications can then continue to read objects, but now they will use the backup on PoINT Archival Gateway. The access point for the S3 client remains the same – a level of transparency provided by Zenko.
If a cloud provider acts as a replication source, it is important to consider possible read costs (egress costs). This problem can be handled by configuring Zenko as a transitory location. Once data is replicated to all targets, it is deleted from its temporary storage point.
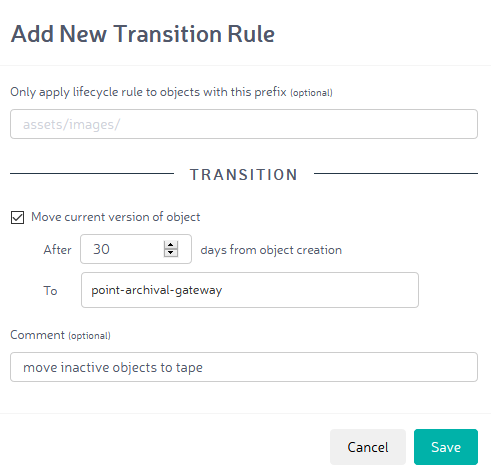
If a copy of the object should not be created on the PoINT Archival Gateway, but instead inactive objects should be archived on this system, you can set this up using a transition rule in Zenko. The following example transfers all objects created over 30 days ago from the primary storage location to the PoINT Archival Gateway. Thanks to tape technology, the price per gigabyte is significantly reduced.
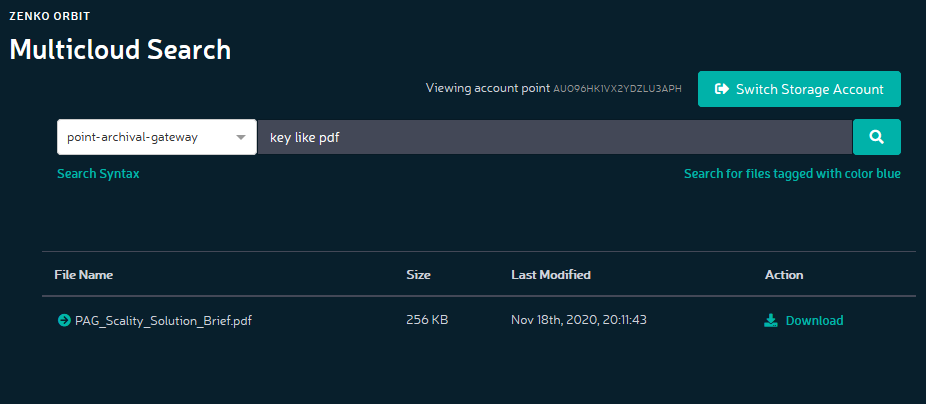
Until now, the S3 REST API has offered no way to search for specific objects. Zenko expands the available functionality using metadata searching. In this case, an S3 GET request has a search parameter added. Alternatively, you can also construct search queries via the Orbit web GUI.