

Previously on our blog, we showed you how the CloudMirror functionality of NetApp StorageGRID can be used to replicate objects. NetApp StorageGRID (SGRID) systems can also be used to set up an in-depth information lifecycle management (ILM) policy. ILM rules can be used to specify the location, duration and protection standards for saving objects. A rule can also be applied to specific objects or buckets. For example, you can create a rule to generate three copies of an object and save each copy to a different data centre for a period of two years. Multiple rules within a policy can also be triggered one after another.
The storage location set within a rule does not have to be an SGRID node; external cloud storage pools are also supported. SGRID lets you set up up to 10 cloud storage pools, where an object is only ever stored in one pool. A cloud storage pool could be an AWS S3 bucket, for example, or an Azure blob container.
You can also integrate the PoINT Archival Gateway via S3. The PoINT Archival Gateway is an S3 object storage system which stores data on tapes instead of hard drives. One big advantage of tape technology is the low cost per gigabyte. PAG is especially good for redundant storage of objects and for long-term archiving.
An object remains visible in SGRID once transferred elsewhere, but its storage location is now the external bucket. Note that SGRID does not store objects in their native format in a cloud storage pool. This means that objects must always be read through SGRID. We’ll have more on this at the end of this article.
To use PAG within an ILM rule, you first need to create a cloud storage pool for this purpose. The necessary steps are as follows:
1. Register with the StorageGRID Tenant Manager.
2. In the menu, under “ILM” select “Storage Pools”.
3. Create a new cloud storage pool, specifying:
- Target name (PoINT Archival Gateway)
- Provider Type: “Amazon S3”
- The PAG’s FQDN and port will be given as the URI (HTTP or HTTPS)
- Target bucket (which must already exist in PAG)
- Access and Secret Key
- Certificate Validation (depending on the certificate used)
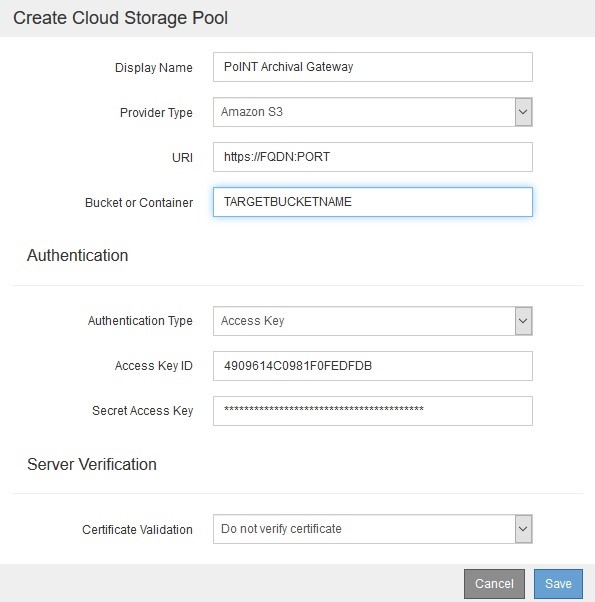
When you save, the connection to PAG will be tested and SGRID will add an object named “x-ntap-sgws-cloud-pool-uuid” to the target bucket. This so-called marker file is used to identify the pool.
You can then set up new ILM rules.
1. In the menu, under “ILM” select “Rules”.
2. You can now specify the name, a description and a filter. The rule can apply to a specific client, for example, or check the bucket name for a specific character string. You can use “Advanced Filtering” to define conditions at the object level – for example, to check the size of objects or search for tags.
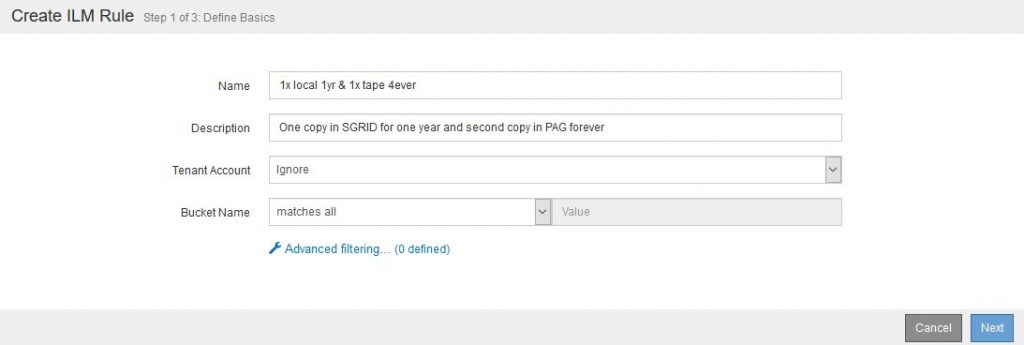
3. In the next dialogue, you can first configure the reference time. The default setting is “Ingest Time”. If you want to use “Last Access Time”, note that changes will not instantly trigger any ILM process (as per the documentation).
Next, specify the storage location and a timeframe. In our example, all objects will be stored for 365 days on SGRID nodes, as well as on tape in PAG in parallel. Objects saved to PAG, however, have no time limit.
The “Retention Diagram” shows a graphical representation of the selection.
4. Depending on the configuration, you may then need to define the system’s behaviour when receiving new objects. The options are “Strict”, “Balanced” and “Dual Commit”.
Once the cloud storage pool and a rule are set up, the ILM policy is next.
1. In the menu, under “ILM” select “Policies”.
2. Click on “Create Proposed Policy”, then name the policy and give a reason for the change. Next, select one or more of the available rules and sort them. Rules are processed from top to bottom, and you will also need to select a default rule. Save the new policy.
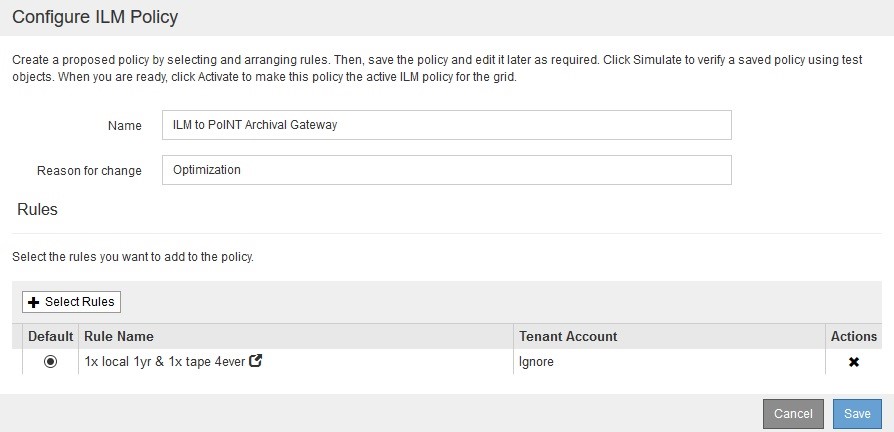
3. Before activating the new ILM policy, you can test the ruleset. Click “Simulate” and enter an existing object in the dialogue. The dialogue will show which rule would be applied to the object.
4. Click “Activate” to enable the new policy immediately.
From now on, objects meeting the specified criteria will be stored on tape by PAG.
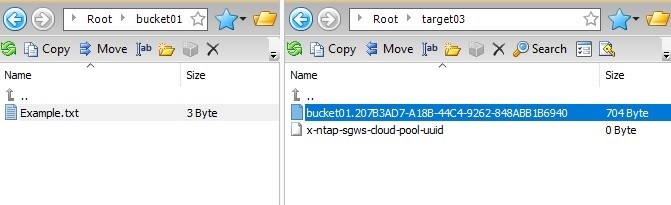
As we mentioned at the beginning, an object stored in a cloud storage pool cannot be read by any program other than StorageGRID. The screenshot below shows an example.
On the left, you can see the object Example.txt in StorageGRID. On the right, you can see the associated object bucket01.207B3AD7-A18B-44C4-9262-848ABB1B6940 in PAG. In other words, the native format is not preserved.
Please note also that the multipart upload size of an S3 client will influence the result in the target folder. For example, if you write an object with a size of 80 MB and a multipart upload size of 5 MB to StorageGRID, 15 objects of 5 MB each will be written to the cloud storage pool.
We appreciate your feedback about the PoINT blog and this blog post. Please contact us at info@point-blog.de.