

Storage tiering has been a well-known concept in IT for decades. It uses prespecified criteria to store data on one of various different classes of storage system. A storage management system which uses the principles of information lifecycle management (ILM), for example, will move files that have not been accessed for a long time to a slower but more cost-effective storage device. While many customers are seeing the benefits of it in their SAN or NAS environments, object storage has until now remained out in the cold.
Object storage systems are basically designed for large volumes of data. The cost per terabyte is usually very attractive, thanks to the use of many large high-density hard drives with efficient erasure coding. Each node often contains 50-70 hard drives, each with a capacity of 8-12 TB. In Summer 2019, Cloudian presented a shared platform with Seagate containing 96 x 16 TB hard drives. This equates to 1.5 PB on just 4 rack units. A good starting size is typically somewhere in the three-digit TB range. But in the age of big data, analytics and IoT, object storage systems fill up quickly.
With more and more data being saved to object storage systems, the question arises as to whether active and inactive objects should both be stored on the same class of system. The hyperscalers are showing the way, offering their customers a wide range of different classes with data transferred automatically in line with their life cycle policy.
If you want to add a second storage class to your private cloud, the first question should be what to do with the inactive objects.A SAN/NAS storage system consists of SSDs and hard drives with varying rpm values (e.g. 15,000, 10,000, 7,200). Hard drives operating at 7,200 rpm already form the basis for object storage systems. The key, then, is to find a storage technology which is more cost-effective for storing inactive data than 7,200 rpm hard drives.
Disregarding the LTO-8 patent dispute between Fujifilm and Sony, which has now come to an end, tapes are widely available. They offer high capacity at a low price and have a promisingly long-term roadmap. LTO-8 media can store 12 TB of data before compression. With IBM TS1160 drives, 3592 media can store 20 TB. LTO-9 is coming soon and will hold up to 24 TB per cartridge.

{kind=link}
In his presentation at the StorageForum in Leipzig in November 2019, Thomas Thalmann, Managing Director of PoINT Software & Systems, explained why tape is recommended as object storage for large data volumes and what needs to be considered when integrating it into a hierarchical storage infrastructure. A recording of the presentation is available here.
The second question: How to write objects to tape
Since object storage systems do not have any direct interface with tape libraries, one idea might be to use software tools to first copy objects to a file system and then transfer them to tape from there. Caution is warranted here however, given the risk of information loss; nevertheless, the very limitations of file systems are what make object storage systems so interesting.
- Avoid
moving data from object storage to file systems
- Limited metadata
- Limited character set
- Limited file name length
- Limited path length
- Limited versioning
- Limited practical number of files
- Overhead from file and folder structure management
At this point, it should be noted once again that LTFS is a file system.
All these limitations lead to one conclusion: the format of data must be preserved. S3 objects, with all their metadata and past versions, must remain S3 objects.
Even so, adding an S3 connection to a file system will still not lead to the desired result.
- Avoid
adding an S3 service to a file system
- Large amounts of storage space required for staging (before writing to tape)
- Unnecessary file system layer with associated performance costs
- Complexity and management overhead
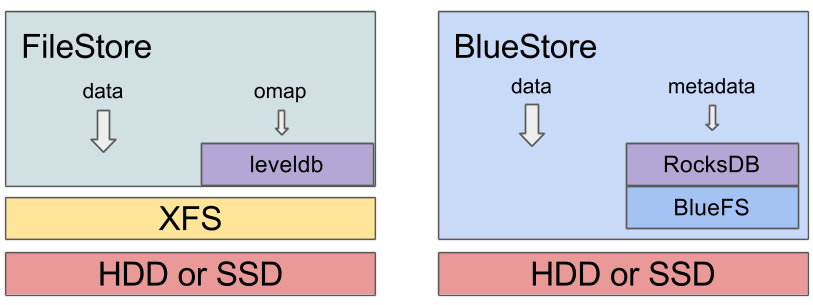
In this context, it is worth looking at what Ceph has developed. Historically, the so-called file store has been used as the storage backend, allowing objects to be saved to an XFS file system. With hindsight, “it was simply the wrong tool for the job”. Instead, BlueStore writes directly to block devices and saves itself the detour.
The complexity of this approach becomes particularly clear when the file system problem is supplemented by the process of transferring data to tape.
The PoINT Archival Gateway (PAG) is a software-based, high-performance S3 object storage system for saving data to tape. PAG’s high level of scalability means it can handle transfer rates of over 1 PB per day. Data security is ensured thanks to erasure coding.
Many hard drive-based object storage systems offer tiering functionality for automatically moving data to a cloud provider via S3. The PoINT Archival Gateway includes such tiering functionality in order to move inactive data from the primary (hard drive-based) storage class to the secondary (tape-based) class.
We appreciate your feedback about the PoINT blog and this blog post. Please contact us at info@point-blog.de.